News
Our paper on predicting crop yield using a multiple-instance
regression approach, "Multiple-Instance Regression with Structured
Data", was accepted to the 4th International Workshop on Mining
Complex Data and will be presented in December, 2008 (Pisa, Italy).
In September 2007, we made our final delivery of PixelLearn to
the USDA's United
States Salinity Laboratory. They are conducting a study that
involves connecting ground estimates of soil salinity with orbital
remote sensing data, and PixelLearn now provides regression
algorithms to accomplish this goal.
About HARVIST
Remote sensing instruments in Earth orbit provide a rich source of
information about current agricultural conditions. Observed over time,
patterns emerge that can assist in the prediction of future conditions,
such as the yield expected for a given crop at the end of the growing
season. It is suspected that these predictions can be made more accurate by
incorporating other sources of information, such as weather conditions from
ground stations, soil properties, etc. The tools required to access and
combine large amounts of data from multiple sources, at different spatial
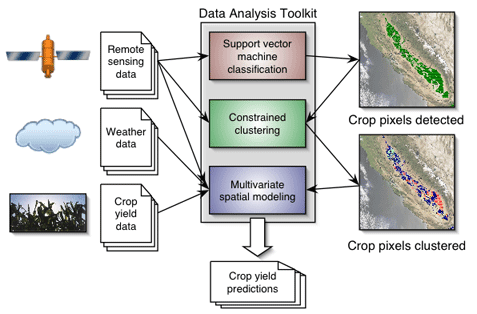
resolutions, are not readily available. The HARVIST (Heterogeneous
Agricultural Research Via Interactive, Scalable Technology) project seeks
to address this lack by demonstrating the technology required to perform
large scale studies of the interactions between agriculture and
climate. Our goal is to integrate multiple Earth Science data sources into
a single graphical user interface that allows for the investigation of
connections between different variables. In particular, we focus on
relationships between weather and crop yield, but the system we are
creating will be capable of integrating data for other studies as well. The
data sources are heterogeneous in that they contain information at
different spatial, spectral, and temporal resolutions. Specifically, we aim
to combine support vector machines (SVMs; classification), clustering
(discovery), and multivariate spatial modeling (regression and prediction)
methods into a single, interactive package to explore the impact of
variables on crop yield.
PixelLearn
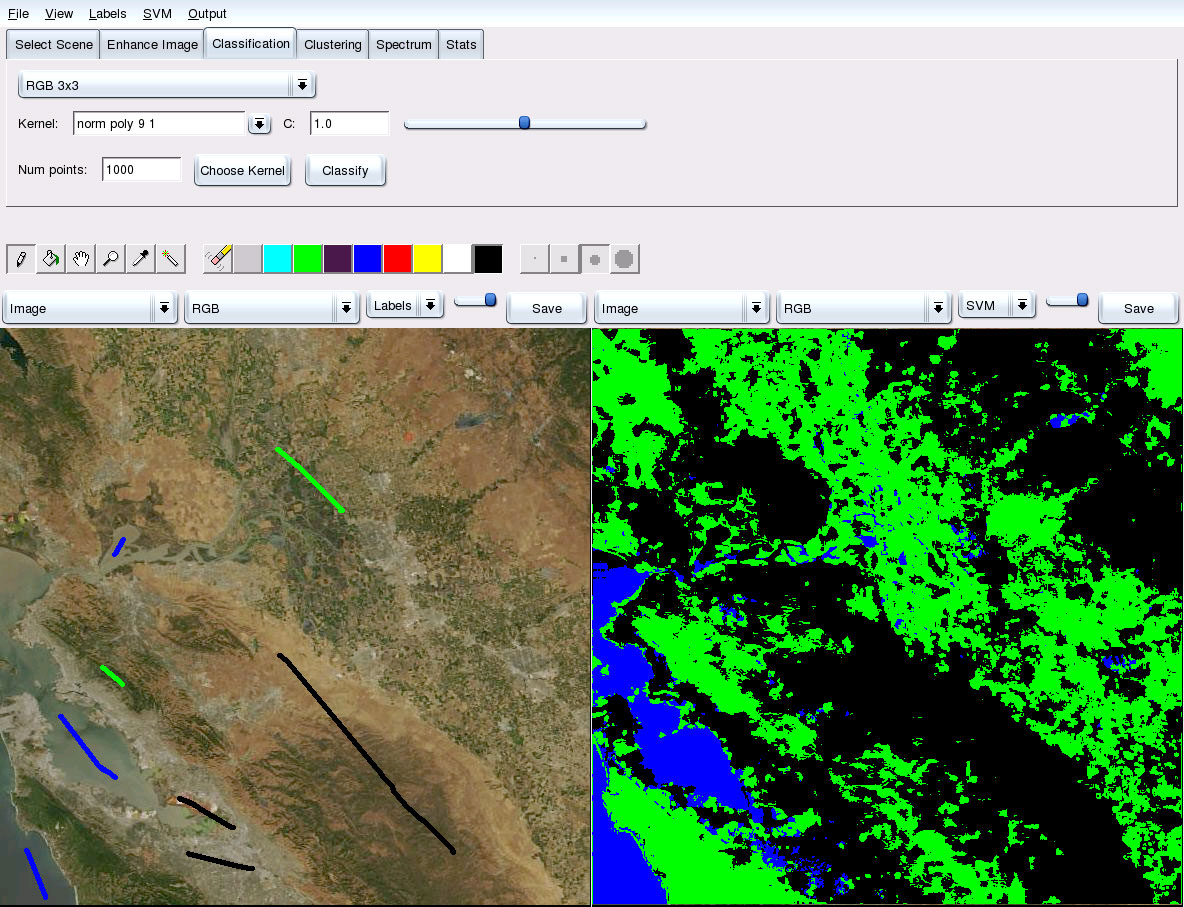
HARVIST uses the graphical PixelLearn system to conduct perform
interactive data labeling and analysis. In the screenshot below,
a remote sensing image of California's Central Valley is shown.
The user has labeled several pixels in the left panel by
"painting" colored labels on them. Here, green indicates
vegetation, blue is water, and black is land. After training an
SVM classifier, the output is shown in the right, in which every
pixel in the image has been assigned to the class that best
describes it. The user can iterate, labeling more pixels and
examining the new SVM output, until the result is satisfactory.
PixelLearn also provides data clustering and regression capabilities.